g2o(General Graphic Optimization),是一个通用图优化算法库,并不限定于某些SLAM问题。可以用图来表达的优化问题都能用g2o解决。由于目前主流的SLAM研究基本都是基于图优化的,本文主要考虑用来解决SLAM问题中的轨迹优化。
在SLAM中应用主要考虑g2o的代码实现上。
>> 待解答问题:
computeError()中的顶点是顺序是怎样定义的?与哪个顶点排序相对应?setToOriginImpl()函数的作用是什么?为什么需要这个函数?_measurement在实际中对应到什么变量吗?计算误差的方程是否有公式对应?SparseBlockMatrix用于求解稀疏矩阵(雅克比和海塞)体现在哪里?SparseBlockMatrix的作用具体是什么linearizeOplus()函数是求残差对于各个顶点(状态)变量(按照顶点顺序)的雅可比矩阵?- 什么时候在哪里加入核函数?
一、需要大概了解的
- 图优化中的顶点是相机位姿,也就是优化变量(状态变量)
- 图优化中的边是指变量之间的变换关系,通常表示误差项
二、g2o结构框架
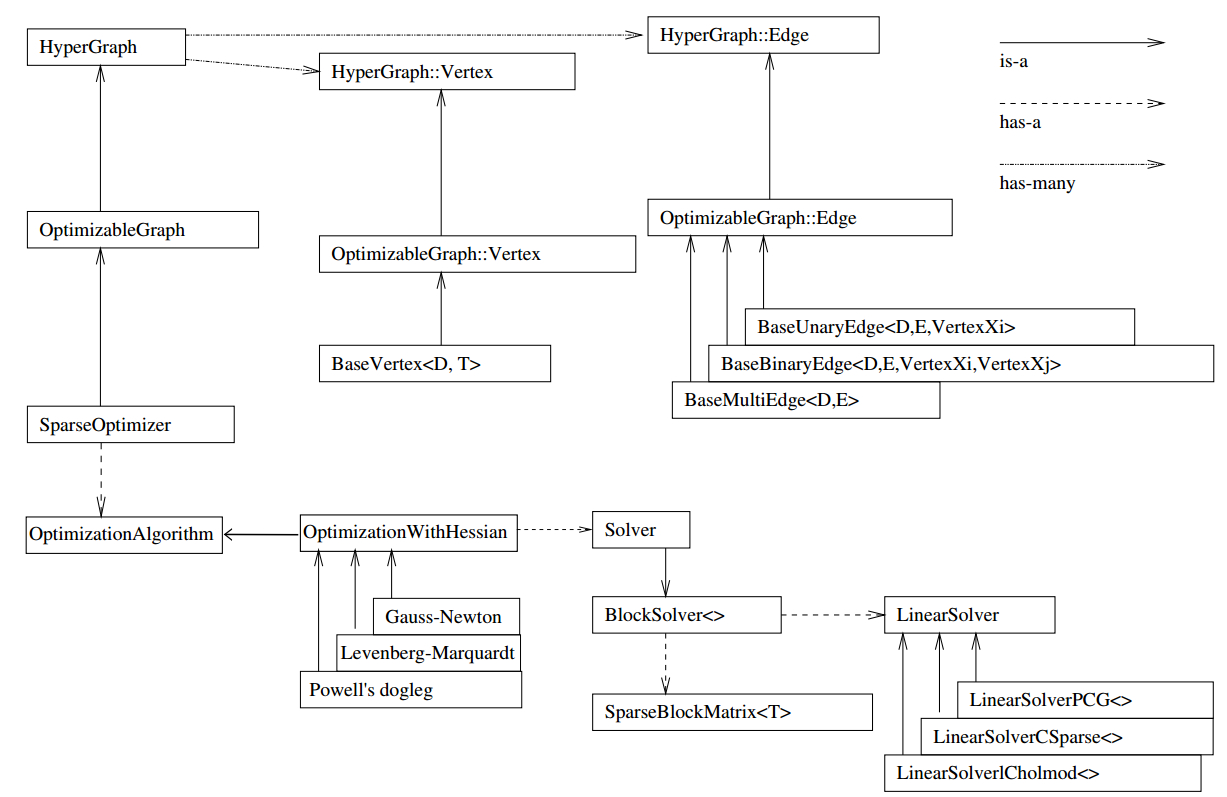
对这个结构框图做一个简单介绍(注意图中三种箭头的含义(右上角注解)) [1] :
(1)整个g2o框架可以分为上下两部分,两部分中间的连接点:SparseOpyimizer 就是整个g2o的核心部分。
(2)往上看,SparseOpyimizer其实是一个Optimizable Graph,从而也是一个超图(HyperGraph)。
(3)超图有很多顶点和边。顶点继承自 Base Vertex,也即OptimizableGraph::Vertex;而边可以继承自 BaseUnaryEdge(单边), BaseBinaryEdge(双边)或BaseMultiEdge(多边),它们都叫做OptimizableGraph::Edge。
(4)往下看,SparseOptimizer包含一个优化算法部分OptimizationAlgorithm,它是通过OptimizationWithHessian来实现的。其中迭代策略可以从Gauss-Newton(高斯牛顿法,简称GN)、 Levernberg-Marquardt(简称LM法),、Powell's dogleg三者中间选择一个(常用的是GN和LM)。
(5)对优化算法部分进行求解的时求解器solver,它实际由BlockSolver组成。BlockSolver由两部分组成:一个是SparseBlockMatrix,它用于求解稀疏矩阵(雅克比和海塞);另一个部分是LinearSolver,它用来求解线性方程\(H\Delta x=-b\)得到待求增量,因此这一部分是非常重要的,它可以从PCG/CSparse/Choldmod选择求解方法。
我们再来看一下框架的搭建步骤,以高博在SLAM十四讲(第二版)中使用g2o求解曲线参数为例:
/*************** 第1步:块求解器类型BlockSolverType*************************/
typedef g2o::BlockSolver< g2o::BlockSolverTraits<3,1> > BlockSolverType; // 每个误差项优化变量维度为3,误差值维度为1
/*************** 第2步:线性求解器类型LinearSolverType*************************/
typedef g2o::LinearSolverDense<BlockSolverType::PoseMatrixType> LinearSolverType;//线性求解器类型
/*************** 第3步:创建总求解器solver。并从GN, LM, DogLeg 中选一个,再用上述块求解器类型和线性求解器类型初始化****/
auto solver = new g2o::OptimizationAlgorithmGaussNewton(
g2o::make_unique<BlockSolverType>(g2o::make_unique<LinearSoverType>()));
/*************** 第4步:创建图优化的核心:稀疏优化器(SparseOptimizer)**********/
g2o::SparseOptimizer optimizer; // 图模型
optimizer.setAlgorithm( solver ); // 设置求解器
optimizer.setVerbose( true ); // 打开调试输出
/*************** 第5步:定义图的顶点和边。并添加到SparseOptimizer中**********/
//往图中增加顶点
CurveFittingVertex* v = new CurveFittingVertex();
v->setEstimate( Eigen::Vector3d(ae,be,ce) );
v->setId(0);
optimizer.addVertex( v );
//往图中增加边
for ( int i=0; i<N; i++ )
{
CurveFittingEdge* edge = new CurveFittingEdge( x_data[i] );
edge->setId(i);
edge->setVertex( 0, v ); // 设置连接的顶点
edge->setMeasurement( y_data[i] ); // 观测数值
edge->setInformation( Eigen::Matrix<double,1,1>::Identity()*1/(w_sigma*w_sigma) ); // 信息矩阵:协方差矩阵之逆
optimizer.addEdge( edge );
}
/*************** 第6步:设置优化参数,开始执行优化**********/
optimizer.initializeOptimization();
optimizer.optimize(100); //设置迭代次数
//输出优化值
Eigen::Vector3d abc_estimate = v->estimate();
如程序中所示,编写一个图优化的程序需要从底层到顶层逐渐搭建,参照g2o官方框架图,步骤可以分为6步:
- 选择你想要的图里的节点与边的类型,确定它们的参数化形式;
- 往图里加入实际的节点和边;
- 选择初值,开始迭代;
- 每一步迭代中,计算对应于当前估计值的雅可比矩阵和海塞矩阵;
- 求解稀疏线性方程\(H_k\Delta x=-b_k\),得到梯度方向;
- 继续用GN或LM进行迭代。如果迭代结束,返回优化值。实际上,g2o能帮你做好第3-6步,你要做的只是前两步而已。下节我们就以一个简单的实例来尝试做这件事。
三、问题描述
假设一个机器人初始起点在0处(用\(x_0\)表示),然后机器人向前移动,通过编码器测得它向前移动了1m,到达第二个地点\(x_1\)。接着,又向后返回,编码器测得它向后移动了0.8米(用\(x_2\)表示)。但是,通过闭环检测,发现它回到了原始起点。可以看出,编码器误差导致计算的位姿和观测到有差异,那机器人这几个状态中的位姿到底是怎么样的才最好的满足这些条件呢? [2]

首先,机器人的位置变换了三次,即\(x_0,x_1,x_2\),其中\(x_0\)位于初始点\(0\)(固定初始点,g2o中一个优化问题,至少需要固定一个顶点),因此,我们把机器人的位置当做顶点,也就是\(x_0,x_1,x_2\)三个顶点。
然后,构建位置之间的关系,即图的边:
\(
\begin{eqnarray}
x_0 &=& 0 &&\mbox{ initial condition}\nonumber\\
x_1 &=& x_0 + 1 &&\mbox{ 1 forward}\nonumber\\
x_2 &=& x_1 - 0.8 &&\mbox{ 0.8 backward}\nonumber\\
x_2 &=& x_0 &&\mbox{ loop closure} \nonumber
\end{eqnarray}\tag{1}\label{problem_edge}
\)
这也就是各个顶点(位置变量)之间的约束关系,那么定义成残差的形式可以表示为:
\(
\begin{eqnarray}
f_1 &=& x_0 = 0 \tag{2.1}\label{2.1}\\
f_2 &=& x_1 - x_0 - 1 = 0\tag{2.2}\label{2.2}\\
f_3 &=& x_2 - x_1 + 0.8 = 0\tag{2.3}\label{2.3}\\
f_4 &=& x_2 - x_0 = 0\nonumber\tag{2.4}\label{2.4}
\end{eqnarray}
\)
线性方程组中变量小于方程的个数,要计算出最优解,需要使用最小二乘法。先构建残差的平方和函数:
\(
c = \sum_{i=1}^{4}f_i^2 = x_0^2 + (x_1 - x_0 - 1)^2 + (x_2 - x_1 + 0.8)^2 + (x_2 - x_0)^2\tag{3}\label{error_square}
\)
为了使残差平方和最小,我们需要让上边的函数对每个变量求偏导,并且要求偏导数为\(0\)。
\(
\begin{eqnarray}
\frac{\partial c}{\partial x_0} &=& 2x_0 - 2(x_1 - x_0 - 1) - 2(x_2 - x_0) &=& 0\nonumber\\
\frac{\partial c}{\partial x_1} &=& 2(x_1 - x_0 - 1) - 2(x_2 - x_1 + 0.8) &=& 0\nonumber\\
\frac{\partial c}{\partial x_2} &=& 2(x_2- x_1 + 0.8) + 2(x_2 - x_0) &=& 0\nonumber
\end{eqnarray}\tag{4}\label{partial}
\)
整理可得
\(
\begin{eqnarray}
3x_0 - x_1 - x_2 &=& -1\nonumber\\
-x_0 + 2x_1 - x_2 &=& 1.8\nonumber\\
-x_0 - x_1 + 2x_2 &=& -0.8\nonumber
\end{eqnarray}\tag{5}
\)
接着矩阵求解线性方程组:
\(
\left[\begin{array}{ccc}
3 & -1 & -1\\
-1 & 2 & -1\\
-1 & -1 & 2
\end{array}\right]
\left[\begin{array}{c}
x_0\\
x_1\\
x_2
\end{array}\right]
=\left[\begin{array}{c}
-1.0\\
1.8\\
-0.8
\end{array}\right]
\mbox{或} \Omega\mu = \xi\tag{6}\label{formula}
\)
那么
\(
\begin{eqnarray}
\mu = \Omega^{-1}\xi &=
\left[\begin{array}{ccc}
3 & -1 & -1\\
-1 & 2 & -1\\
-1 & -1 & 2
\end{array}\right]^{-1}
\left[\begin{array}{c}
-1.0\\
1.8\\
-0.8
\end{array}\right]\nonumber\\
&= \left[\begin{array}{ccc}
1 & 1 & 1\\
1 & 5/3 & 4/3\\
1 & 4/3 & 5/3
\end{array}\right]
\left[\begin{array}{c}
-1.0\\
1.8\\
-0.8
\end{array}\right]=\left[\begin{array}{c}
0\\
0.93\\
0.07
\end{array}\right]\nonumber\\
\end{eqnarray}\tag{7}\label{solve_the_problem}
\)
所以优化后,为满足这些边的约束条件,机器人的位置应该为\(x_0 = 0, x_1 = 0.93,x_2 = 0.07\), 可以看到,因为有了\(x_2\rightarrow x_0\)的闭环检测,几个位置点间才能形成互相约束。
四、g2o解决该优化问题
然后尝试用g2o来解决上边的问题,以便理解如何使用g2o[3]。
4.1 定义顶点类
从问题描述的开始就说明了顶点定义为机器人的位置变量,也就是\(x_0,x_1,x_2\),在图优化中, 一个顶点可以包含多个需优化量。比如二维环境下的机器人位置一般是3维的(x,y,theta),即一个顶点有三个需要优化的量。而在该问题中,机器人位置变量为1维,因此,我们只需要优化求解一个1维的距离值。机,一个顶点只包含一个需优化量。
// 模型的顶点,模板参数:优化变量维度和数据类型
class SimpleVertex : public g2o::BaseVertex<1, double> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
SimpleVertex(bool fixed = false)
{
setToOriginImpl();
setFixed(fixed);
}
SimpleVertex(double e, bool fixed = false)
{
_estimate = e;
setFixed(fixed);
}
// 重置
virtual void setToOriginImpl() override {
_estimate = 0;
}
// 更新
virtual void oplusImpl(const double *update) override {
_estimate += *update;
}
// 存盘和读盘:留空
virtual bool read(istream &in) {return true;}
virtual bool write(ostream &out) const {return true;}
};
上面代码中g2o::BaseVertex<1, double>就表示了优化的量是一维的,数据类型是double
EIGEN_MAKE_ALIGNED_OPERATOR_NEW是一个宏,用于在Eigen 的C++库中启用对齐内存分配。 因为Eigen库为了使用SSE加速,在内存上分配了128位的指针,涉及字节对齐问题,所以在使用到Eigen库的地方都需要在public下添加该宏,如果不添加该宏,在编译时不会报错,在运行时会报错。
自定义一个顶点通常需要重新实现setToOriginImpl()和oplusImpl(const double read(istream &in)和write(ostream &out)是为了保存和读取当前顶点数据到本地,一般可留空。setToOriginImpl()函数用于重置顶点的数据,一般是赋初值\(0\)。顶点包含的数据变量是_estimate,该变量的类型即是g2o::BaseVertex<1, double>中设置的double。该函数是用于重置_estimate和使顶点恢复默认状态。oplusImpl(const double update)函数用于叠加优化量的步长。之所以需要重新定义以上两个函数,主要原因就是有时候这样的叠加操作并不是线性的,比如2D-SLAM中位姿(变量中包含旋转)步进叠加操作则不是线性的,而在此问题中我们是直接线性叠加一维的距离值_estimate += *update;。
另外,顶点是可以设置成固定的。当不需要变动某个顶点时,使用setFixed函数来固定。通常,一个优化问题中,至少需要固定一个顶点,否则所有的顶点都在浮动,优化效果也不会好。
4.2 定义边的类
边就是顶点之间的约束关系。在该问题中就是两位置间的测量值和观测值之间的差值要趋近于0。这里需要定义的边其实就是公式\(\eqref{problem_edge}\)和\(\eqref{2.1}-\eqref{2.4}\)中的约束关系。
实际上,G2O中边有三种:一元边(g2o::BaseUnaryEdge),二元边(g2o::BaseBinaryEdge)和多元边(g2o::BaseMultiEdge)。
g2o::BaseUnaryEdge<D, E, VertexXi> g2o::BaseBinaryEdge<D, E, VertexXi, VertexXj> g2o::BaseMultiEdge<D, E>
不同类型的边有不同数量的模板参数。其中D 是 int 型,表示误差值的维度 (dimension), E 表示测量值的数据类型(即_measurement的类型), VertexXi,VertexXj 分别表示不同顶点的类型。当D为2时,_error的类型变为Eigen::Vector2d,当D为3时,_error的类型变为Eigen::Vector3d。
例:BaseBinaryEdge<2, Vector2D, VertexSBAPointXYZ, VertexSE3Expmap>
上面这行代码表示二元边,参数1是说测量值是2维的;参数2对应测量值的类型是Vector2D,参数3和4表示两个顶点也就是优化变量分别是三维点 VertexSBAPointXYZ,和李群位姿VertexSE3Expmap。
在高博的《自动驾驶与机器人中的SLAM技术:从理论到实践》中,第四章关于预计分的边EdgeInertial因为涉及到位姿、速度、陀螺仪零偏和加速度计零偏四种顶点类型,所以那里的EdgeInertial是继承自g2o::BaseMultiEdge,也就是多元边。

在该问题中,公式\(\eqref{2.1}-\eqref{2.4}\)中有一个一元边\(\eqref{2.1}\)和三个二元边\(\eqref{2.2}-\eqref{2.4}\)。在g2o中定义如下:
// 一元边的误差模型 模板参数:测量值维度,测量值类型,连接顶点类型
class SimpleUnaryEdge : public g2o::BaseUnaryEdge<1, double, SimpleVertex> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
SimpleUnaryEdge() : BaseUnaryEdge() {}
// 计算模型误差
virtual void computeError() override {
const SimpleVertex *v = static_cast<const SimpleVertex *> (_vertices[0]);
const double abc = v->estimate();
_error(0, 0) = _measurement - abc;
}
// 计算雅可比矩阵
virtual void linearizeOplus() override {
//此处就是求前边这个computeError()函数中误差_error相对于abc变量的导数
_jacobianOplusXi[0] = -1;//一元边只有一个顶点,所以只有_jacobianOplusXi。_jacobianOplusXi的维度和顶点需优化的维度是一致的
}
virtual bool read(istream &in) {}
virtual bool write(ostream &out) const {}
};
// 二元边误差模型 模板参数:测量值维度,测量值类型,连接顶点类型
class SimpleBinaryEdge : public g2o::BaseBinaryEdge<1, double, SimpleVertex, SimpleVertex> {
public:
EIGEN_MAKE_ALIGNED_OPERATOR_NEW
SimpleBinaryEdge() {}
// 计算模型误差
virtual void computeError() override {
const SimpleVertex *v1 = static_cast<const SimpleVertex *> (_vertices[0]);
const SimpleVertex *v2 = static_cast<const SimpleVertex *> (_vertices[1]);
//这里_vertices[0]和_vertices[1]表示的顶点通过setVertex(idx,Vertex[i])来确定。与后续的添加边相对应
const double abc1 = v1->estimate();
const double abc2 = v2->estimate();
_error[0] = _measurement - (abc1 - abc2);//这里写的是一个二元边残差的统一定义形式,针对公式(2.1)-(2.4)的具体残差定义,后续会根据添加边中的setVertex()函数和setMeasurement()函数来实现。
}
// 计算雅可比矩阵
virtual void linearizeOplus() override {
_jacobianOplusXi(0,0) = -1;//在此处就是求_error[0] = _measurement - (abc1 - abc2)对于abc1的偏导数。二元边有两个顶点,偏差_error对每个顶点的偏导数都需要求解;如果_error是多维的,则每一维的偏导都需要求解。即会出现_jacobianOplusXi(1,0)
_jacobianOplusXj(0,0) = 1;//在此处就是求_error[0] = _measurement - (abc1 - abc2)对于abc2的偏导数。因为误差_error只有一维,所以_jacobianOplusXi只有_jacobianOplusXi(0,0)项。此时_jacobianOplusXi[0]与_jacobianOplusXi(0,0)效果等价。
}
virtual bool read(istream &in) {}
virtual bool write(ostream &out) const {}
};
因为我们这里测量值是一维的距离值(double类型)而顶点类型为SimpleVertex,所以一元边和二元边分别设置成g2o::BaseUnaryEdge<1, double, SimpleVertex>和g2o::BaseBinaryEdge<1, double, SimpleVertex, SimpleVertex>类型。
自定义边同样需要特别关注两个函数computeError()和linearizeOplus()。
computeError()是用于计算迭代误差的,顶点间的约束正是由误差计算函数构建的,优化时误差项将逐步趋近于0。_error的维度和类型通常由构建的模型决定,比如该问题中误差为距离误差。
linearizeOplus()函数里主要是配置雅克比矩阵,也就是残差相对于各个顶点(优化变量)的偏导数(雅可比矩阵)的解析求导函数。当然,g2o是支持自动求导的,该函数可以不实现,若不手动实现,优化时g2o会使用内置的数值求导,但数值求导速度慢。准确的手动配置雅可比矩阵可加快优化计算的速度。雅克比矩阵的计算方法:以上边二元边的定义为例,computeError()函数中定义了_error变量的计算方程,那么雅可比矩阵就是求解该_error变量相对于各个顶点(abc1和abc2)在该方程中的偏导数,如以上的代码中_jacobianOplusXi(0,0)和_jacobianOplusXj(0,0)所示。
4.3 创建优化器
这个与前边g2o求解曲线参数的优化框架的搭建步骤相同
// 构建图优化,先设定g2o
typedef g2o::BlockSolver<g2o::BlockSolverTraits<1, 1>> BlockSolverType; // 每个误差项优化变量维度为1,误差值维度为1
typedef g2o::LinearSolverDense<BlockSolverType::PoseMatrixType> LinearSolverType; // 线性求解器类型
// 梯度下降方法,可以从GN, LM, DogLeg 中选
auto solver = new g2o::OptimizationAlgorithmGaussNewton(
g2o::make_unique<BlockSolverType>(g2o::make_unique<LinearSolverType>()));
g2o::SparseOptimizer optimizer; // 图模型
optimizer.setAlgorithm(solver); // 设置求解器
optimizer.setVerbose(true); // 打开调试输出
BlockSolver可设成固定的,也可以设成动态的。
下面是本人对于BlockSolver设置的理解,不一定正确。仅为参考。
优化变量的维度通常是明确的,但误差项的维度可能是变化的。每条边的误差项维度可能都不一样。这时应该使用g2o::BlockSolverX,以便能动态适应误差项的维度。
linear solver也是可选的。主要有下面几种可选:
g2o::LinearSolverCSparse g2o::LinearSolverCholmod g2o::LinearSolverEigen g2o::LinearSolverDense g2o::LinearSolverPCG
不同的linear solver有不同的依赖,需要注意是否已经安装了相应的依赖。
4.4 添加顶点
// 往图中增加顶点 std::vector<SimpleVertex *> vertexs; //x0 SimpleVertex *v = new SimpleVertex(); v->setEstimate(0);//估计初始值,这里应该是取给定的初始估计值或者上一步的优化值 v->setId(0); v->setFixed(true);//将x0这个顶点设置为固定 optimizer.addVertex(v); vertexs.push_back(v); //x1 SimpleVertex *v1 = new SimpleVertex(); v1->setEstimate(1); v1->setId(1); optimizer.addVertex(v1); vertexs.push_back(v1); //x2 SimpleVertex *v2 = new SimpleVertex(); v2->setEstimate(0.1); v2->setId(2); optimizer.addVertex(v2); vertexs.push_back(v2);
这里添加顶点是比较简单的,只需要将几个顶点添加上即可,注意顶点的id确保不能重复即可。其中,顶点可使用setEstimate接口设置初始值,当然在实际系统中,这个初始值应该是我们的先验值。
接下来添加边的过程比较重要,且需要注意与边的类的关联。
4.5 添加边
// 往图中增加边 SimpleUnaryEdge *edge = new SimpleUnaryEdge(); // edge->setId(i); edge->setVertex(0, vertexs[0]); // 设置连接的顶点 edge->setMeasurement(0); // 观测数值 edge->setInformation(Eigen::Matrix<double, 1, 1>::Identity()); // 信息矩阵:协方差矩阵 optimizer.addEdge(edge); SimpleBinaryEdge * edge1 = new SimpleBinaryEdge(); // edge->setId(i);//id 不设置似乎没有关系,如果设置需要每条边设置成不一样的 edge1->setVertex(0, vertexs[1]);//这里设置的序号对应的顶点要和边的computeError函数里设定的顶点是一一对应的 edge1->setVertex(1, vertexs[0]); // 设置连接的顶点 edge1->setMeasurement(1); // 观测数值 edge1->setInformation(Eigen::Matrix<double, 1, 1>::Identity()*1.0); // 信息矩阵:协方差矩阵之逆 optimizer.addEdge(edge1); SimpleBinaryEdge * edge2 = new SimpleBinaryEdge(); // edge->setId(i); edge2->setVertex(0, vertexs[2]); // 设置连接的顶点 edge2->setVertex(1, vertexs[1]); // 设置连接的顶点 edge2->setMeasurement(-0.8); // 观测数值 edge2->setInformation(Eigen::Matrix<double, 1, 1>::Identity()); // 信息矩阵:协方差矩阵之逆 optimizer.addEdge(edge2); SimpleBinaryEdge * edge3 = new SimpleBinaryEdge(); // edge->setId(i); edge3->setVertex(0, vertexs[2]); // 设置连接的顶点 edge3->setVertex(1, vertexs[0]); // 设置连接的顶点 edge3->setMeasurement(0); // 观测数值 edge3->setInformation(Eigen::Matrix<double, 1, 1>::Identity()); // 信息矩阵:协方差矩阵之逆 optimizer.addEdge(edge3);
边也有setId接口,但不设置好像也可以,如果设置也需确保不重复。但id号的顺序似乎并没有要求。
使用setVertex接口设置顶点时是有顺序的,这个顺序与边的computeError函数中使用顶点的顺序要对应起来。以公式\(\eqref{2.2}\)(\(f=x_1-x_0-1=0\))为例,对应的约束边为edge1,
SimpleBinaryEdge * edge1 = new SimpleBinaryEdge(); // edge->setId(i);//id 不设置似乎没有关系,如果设置需要每条边设置成不一样的 edge1->setVertex(0, vertexs[1]);//这里设置的序号对应的顶点要和边的computeError函数里设定的顶点是一一对应的 edge1->setVertex(1, vertexs[0]); // 设置连接的顶点 edge1->setMeasurement(1); // 观测数值 edge1->setInformation(Eigen::Matrix<double, 1, 1>::Identity()*1.0); // 信息矩阵:协方差矩阵之逆 optimizer.addEdge(edge1);
其中,添加顶点的顺序为
edge1->setVertex(0, vertexs[1]);//vertexs[1]对应顶点x1 edge1->setVertex(1, vertexs[0]);//vertexs[0]对应顶点x0
相对应的在computeError()函数中,顶点v1(abc1)就对应到x1,顶点v2(abc2)就对应到x0,因此,残差的定义就是_error[0]=_measurement - (x1 - x0),由此可以得到_measurement就是1,与代码中设置的观测数值相同。这也就解释了 setMeasurement()函数的作用。
各个边结合computeError()函数就对应到了约束函数公式\(\eqref{2.1}-\eqref{2.4}\)。
setInformation接口用于设置信息矩阵。信息矩阵是方阵,其行列数由误差项的维度决定。信息矩阵的具体作用在下面这一部分详细说明。
4.6 执行优化
optimizer.initializeOptimization();
optimizer.optimize(10);//迭代次数
//输出优化结果
cout << "esimated model: " << vertexs[0]->estimate() << " "
<< vertexs[1]->estimate() << " " << vertexs[2]->estimate() << " " << endl;
这样可以得到最终优化求解的结果为:
start optimization iteration= 0 chi2= 0.013333 time= 6.547e-06 cumTime= 6.547e-06 edges= 3 schur= 0 iteration= 1 chi2= 0.013333 time= 1.285e-06 cumTime= 7.832e-06 edges= 3 schur= 0 iteration= 2 chi2= 0.013333 time= 4.4e-07 cumTime= 8.272e-06 edges= 3 schur= 0 iteration= 3 chi2= 0.013333 time= 4.19e-07 cumTime= 8.691e-06 edges= 3 schur= 0 iteration= 4 chi2= 0.013333 time= 6.07e-07 cumTime= 9.298e-06 edges= 3 schur= 0 iteration= 5 chi2= 0.013333 time= 4.08e-07 cumTime= 9.706e-06 edges= 3 schur= 0 iteration= 6 chi2= 0.013333 time= 3.9e-07 cumTime= 1.0096e-05 edges= 3 schur= 0 iteration= 7 chi2= 0.013333 time= 4.08e-07 cumTime= 1.0504e-05 edges= 3 schur= 0 iteration= 8 chi2= 0.013333 time= 3.96e-07 cumTime= 1.09e-05 edges= 3 schur= 0 iteration= 9 chi2= 0.013333 time= 4.03e-07 cumTime= 1.1303e-05 edges= 3 schur= 0 solve time cost = 0.000384255 seconds. estimated model: 0 0.933333 0.0666667
和刚才用线性方程组\(\eqref{solve_the_problem}\)求解得到的结果基本一致。
回到刚才的信息矩阵,如果在一次优化中,对于某一次测量,我们有十足的把握,它非常的准确,所以优化时我们希望对于这次测量给与更高的权重。 比如对于约束边edge1,也就是:机器人向前移动,通过编码器测得它向前移动了1m,到达第二个地点\(x_1\),而我们对于编码器的测量精度非常自信,那么我们可以将edge1的信息矩阵设置为:
edge1->setInformation(Eigen::Matrix<double, 1, 1>::Identity()*10.0);
然后再次运行优化程序,得到的结果为:
start optimization iteration= 0 chi2= 0.019048 time= 6.006e-06 cumTime= 6.006e-06 edges= 3 schur= 0 iteration= 1 chi2= 0.019048 time= 1.16e-06 cumTime= 7.166e-06 edges= 3 schur= 0 iteration= 2 chi2= 0.019048 time= 4.69e-07 cumTime= 7.635e-06 edges= 3 schur= 0 iteration= 3 chi2= 0.019048 time= 4.7e-07 cumTime= 8.105e-06 edges= 3 schur= 0 iteration= 4 chi2= 0.019048 time= 4.38e-07 cumTime= 8.543e-06 edges= 3 schur= 0 iteration= 5 chi2= 0.019048 time= 4.06e-07 cumTime= 8.949e-06 edges= 3 schur= 0 iteration= 6 chi2= 0.019048 time= 4.33e-07 cumTime= 9.382e-06 edges= 3 schur= 0 iteration= 7 chi2= 0.019048 time= 4.07e-07 cumTime= 9.789e-06 edges= 3 schur= 0 iteration= 8 chi2= 0.019048 time= 4.14e-07 cumTime= 1.0203e-05 edges= 3 schur= 0 iteration= 9 chi2= 0.019048 time= 4.13e-07 cumTime= 1.0616e-05 edges= 3 schur= 0 solve time cost = 0.000371893 seconds. estimated model: 0 0.990476 0.0952381
可以发现,优化结果中\(x_1\)更接近1的位置,说明我们此时更相信编码器测量的从\(x_0\)到\(x_1\)的距离值。
4.7 鲁棒核函数
我们在采集数据过程中,不可避免的会出现一些很离谱的错误点,也叫野值/外点。由于这些外点的存在,会导致优化过程被外点拉偏。g2o中的鲁棒核函数就是为了抑制某些误差特别大的点,避免被外点拉偏整个优化结果。
鲁棒核函数不是g2o特有的,这是非线性优化方法中的一种常用手段!类似的还有RANSAC(随机采样一致性)。
使用方法如下:
//构造一个Huber鲁棒核函数 auto* rk = new g2o::RobustKernelHuber; rk->setDelta(200.0);//设置delta大小,注意这个要根据实际的应用场景去尝试,然后选择合适的大小 edge->setRobustKernel(rk);//向边中添加鲁棒核函数
>> 解答文章开头的问题
- computeError中的顶点是顺序是怎样定义的?与哪个顶点排序相对应?computeError中的顶点只是定义中间变量,具体的中间变量是代指哪个顶点是通过顶点定义时的排序和在添加边时
edge->setVertex(idx, vertexs[i])确定的,这里的idx就是该约束边中顶点的序号,这个序号就对应了顶点数组vertexs中的顶点vertexs[i]。 - setToOriginImpl()函数的作用是什么?为什么需要这个函数?查了很久,发现就是一个顶点变量的重置,重置为一个初始值,连官方说明文档也只是说
Additionally,setToOriginImpl() that should set the internal state of the vertex to 0 has to specified.
主要的原因可能就是顶点变量的类型各不相同,变量的重置(初始化)需要手动实现。
- _measurement在实际中对应到什么变量吗?计算误差的方程是否有公式对应? 这个在定义边的类中的
二元边的误差模型代码中有说明,computeError()函数中写道:_error[]是一个二元边残差的统一定义形式,针对公式(2.1)-(2.4)的具体残差定义,后续会根据添加边中的setVertex()函数和setMeasurement()函数来实现。
结合添加边中的说明,可以理解_measurement变量,同时可以明白_measurement变量的值是由
setMeasurement()函数来给定的。 - SparseBlockMatrix用于求解稀疏矩阵(雅克比和海塞)体现在哪里?SparseBlockMatrix的作用具体是什么主要是g2o内部实现的,以下为个人理解:稀疏矩阵中的非零项很少,以至于\(0\)元素的存储会占据绝大部分内存,那么通过SparseBlockMatrix不存储零矩阵,避免与零矩阵做加减乘除运算,提高运算效率。当然这只是SparseBlockMatrix的其中一个作用。
- linearizeOplus()函数是求残差对于各个顶点(状态)变量(按照顶点顺序)的雅可比矩阵?是的,以代替g2o内置的数值求导,提高运算效率。在定义边的类部分最后有说明。
- 什么时候在哪里加入核函数?在鲁棒核函数部分有单独说明。
本篇对应代码项目为:
git clone https://gitee.com/mazhg/g2o-simple-test.git
参考文献:
[1] 高翔, 自动驾驶与机器人中的SLAM技术:从理论到实践[M], 北京:电子工业出版社, 2023.
[2] https://zhuanlan.zhihu.com/p/121628349
[3] https://heyijia.blog.csdn.net/
[4] https://www.zhihu.com/question/551240523
[…] 采用g2o使用说明中相同的优化问题,简要描述如下: […]